Disclaimer: As an attendee of Tech Field Day 19, my flights, accommodations, and other expenses were paid for by Tech Field Day. I was not required to write about any of the content presented, and I have not been compensated in any way for this post. Some presenting companies chose to provide gifts to attendees; any such gifts do not impact my reviews or opinions as expressed on this site. All opinions in this post are my own, and do not necessarily represent that of my employer or Gestalt IT.
The first presenting company of Tech Field Day 19 (TFD19) was Ixia. The focus of their presentation surrounded their network visibility offerings. I’m not going to elaborate on all of the details of their presentations. I would instead encourage you to check them out:
- Ixia Company Introduction
- Ixia Network Visibility Fundamentals
- Ixia Introducing the Vision X Network Packet Broker
- Ixia Visibility and Performance Monitoring with the Vision Edge 1S
- Ixia Public, Private, and Hybrid Cloud Visibility
My Thoughts
Although I have a pretty solid understanding of networking principles and regularly spend time troubleshooting problems around the network stack, the products in Ixia’s visibility platform are beyond the scope of what I do daily. Despite that, it’s easy to see where their product line would fit into an enterprise company. They strive to offer increased visibility into network traffic from the datacenter, to the edge, and all the way to the cloud. Companies need to increase security within their networks, but they can’t do that without knowing what is happening within them.
“The number one driver for visibility is security.”
–Recep Ozdag – VP and GM of Network Visibility, Ixia
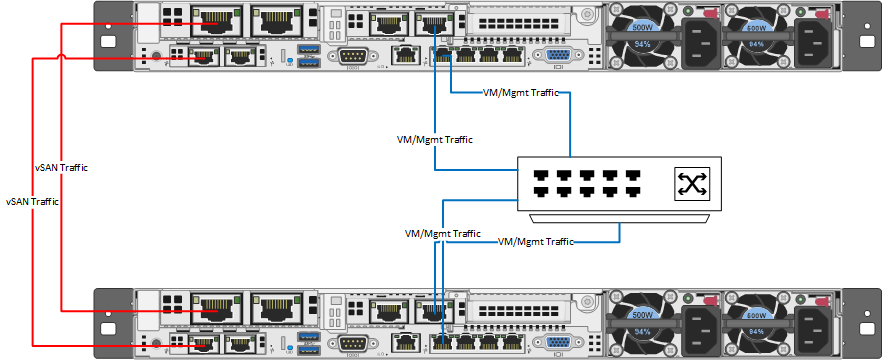
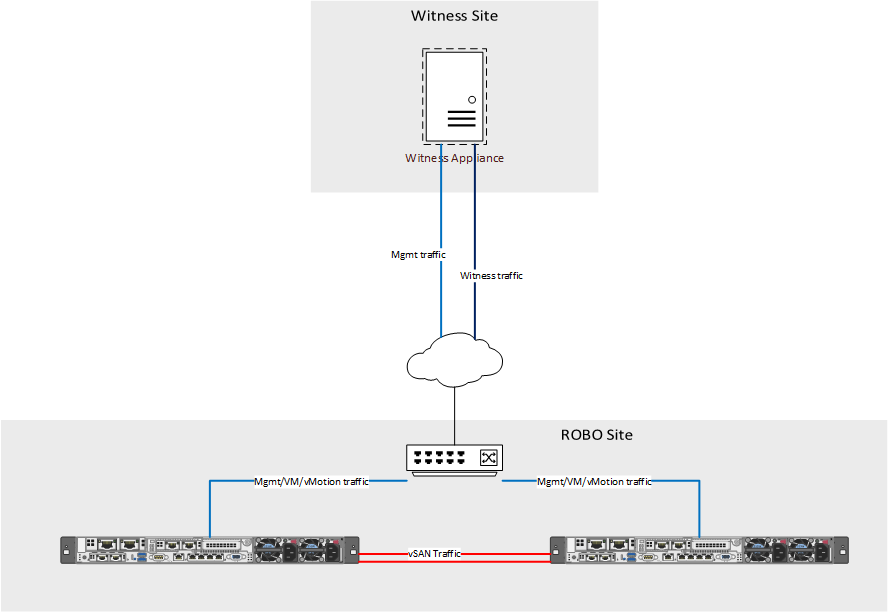
They leverage network taps to pass traffic, packet brokers to organize, aggregate and filter traffic, and also offer options to do the same in the cloud. You are then able to wrap rules and policies around the packet brokers to dictate what traffic is directed to your existing network security tool set, and how much of it. If that seems a little confusing, this diagram of theirs may help.
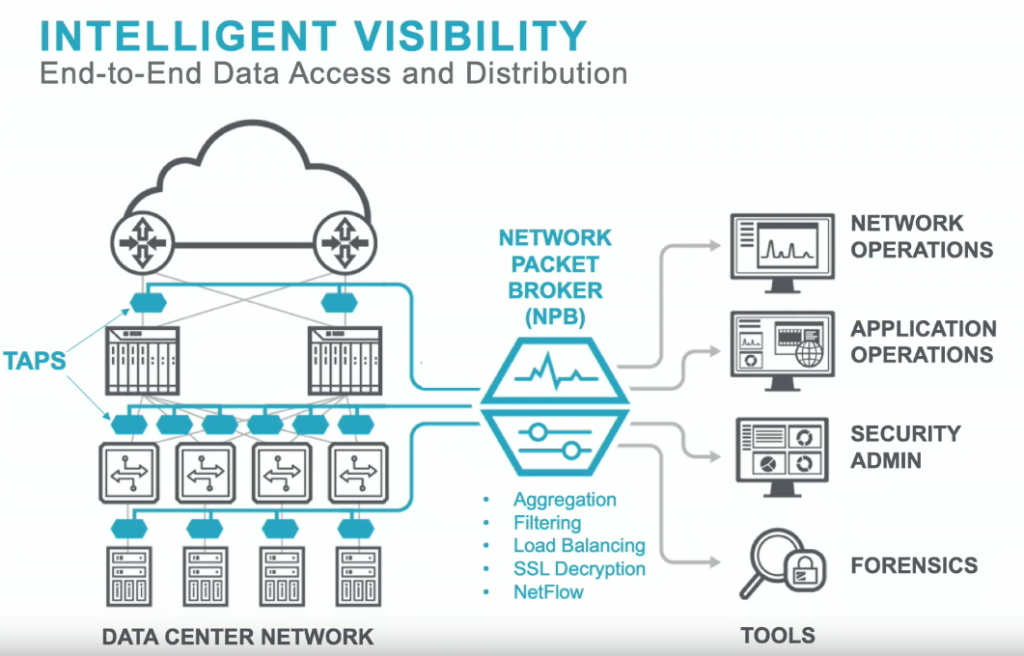
You may be asking yourself, “Why would I want this?” Perimeter security is great, but it is only a small part of the picture when it comes to securing a network. Enterprise networks create an immense amount of traffic, a large portion of which never touches the perimeter. Trying to funnel all of that traffic through a traditional set of security tools will likely overrun what the tools are capable of processing, or will land you a crazy-high licensing bill for those tools whose pricing are based on ingestion rates. That’s where the beauty of the traffic broker comes in. It allows you to wrap policies around traffic flow to intelligently trim and route packets to your existing security tools in order to maximize their utility.
I’m not going to get any further into the weeds on how it all works (that’s what the presentations are for). If you’re wondering if this type of product is right for you, let’s take a look at this customer statistic they displayed:

Those are some impressive numbers on large companies! However, my guess is that’s because their product is geared towards those large companies. I would be interested to see their customer numbers in the small/medium sized business areas.
Unfortunately, Ixia only had an hour to present at TFD19 and likely didn’t have time to do a demonstration of the platform. They did show us a few screenshots of the UI, and honestly it felt a little dated. I can’t speak to the usability of the interface as I didn’t see it in action, but it does remind me of the iLO2 interfaces from the HPE days of old. Given their customer base, I would assume that the interface functions as expected. I was just hoping for something a little more modern.
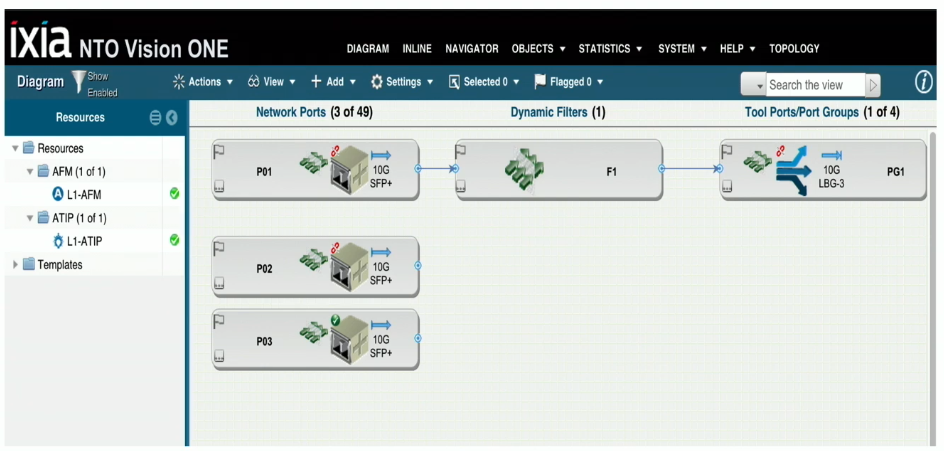
TL;DR
Even though the UI leaves a little to be desired, Ixia offers a comprehensive portfolio of products that will help collect, aggregate, and filter network packets in order to maximize the effectiveness of a customer’s existing security tools. I would love to see how Ixia can tailor a solution to help the small businesses of the world achieve similar visibility.